Learn Framework
This is the repository for the learn framework
Getting started
Create New Conda Environment and install backend framework
Framework repo is located at https://gitlab.lollllz.com/learn/framework.git or at
https://gitlab.kitware.com/learn/framework.git
This will also install the learn framework as the last step (assuming you are in the root of this project):
conda create --name learn python=3.7 torchvision numpy scikit-learn \
jupyter ipython seaborn requests pyarrow pandas \
pytorch torchvision cudatoolkit=10.2 -c pytorch
conda activate learn
git lfs install
# Install the framework and learn packages
cd ..
git clone https://gitlab.lollllz.com/learn/framework.git
cd framework
pip install -r requirements.txt
pip install -e .
cd ../learn
pip install -r requirements.txt
pip install -e .
git lfs pull- Note, you may use previous environment from conda but this step makes sure you have the most up-to-date libraries and has been tested.
- Note, development is latest branch right now.
- Note,if doing object detection, you must also install detectron witht he following code:
pip install cython; pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'For the algorithms you want to run (folders inside algorithm folder),
requirements in the requirements.txt using pip install (best practice to put all your requirements here even if in the part above). Some requirements are also met in the main requirements in the root of this project.
pip install -r algorithms/<algo name>/requirements.txtInstall framework (instructions above)
You will need to download all the datasets for evaluation and follow instructions from: https://gitlab.lollllz.com/lwll/dataset_prep. You can then symbolically link a "development" link to the external folder (in the same folder as external) so you don't have to download the data twice. All datasets would be best if you have the room and want to test out with different source datasets.
Run the learn protocol with
You can run any of the the configurations in the
framework -a learn/algorithms -i JPLInterface -p configs/<config_file>.yaml learn/protocol/learn_protocol.pyThe config options are explained in learn/protocol/learn_config.py
Download the data
You need to download the data in order to run the experiment from: https://gitlab.lollllz.com/lwll/dataset_prep Please download all the dataset to run everything. For minimal work examples, image classsification needs mnist and object detection also needs face_detection. Follow instructions there to download it at least those datasets.
Protocol Parameters
There is a file in learn/protocol/learn_config.py which defines where the configuration of the
protocol (overall running parameters). These include dataset directory, which tasks you want to run, and more.
You may modify this config for your computer.
For the local protocol you will be running, tasks are defined in learn/protocol/localinterface.json.
Design of the Framework
The framework is divided into protocol (framework) and algorithms. The protocol organizes and runs the algorithms, and the algorithms do the active learning. There are four different types of algorithms for this protocol.
- Domain/Network Selection - Selects the domain and pretrained network that define the source dataset for each task
- Select Algorithms - Selects which algorithms to run given a source and target dataset
- Query Strategy - The Active Learning Query Strategy that first selects the unlabeled data which would be most impactful for labeling.
- Adaption Algorithm - The algorithm which creates a classification for the target task. This can either be image classification, object detection, or machine translation.
The overall problem and protocol is defined below:
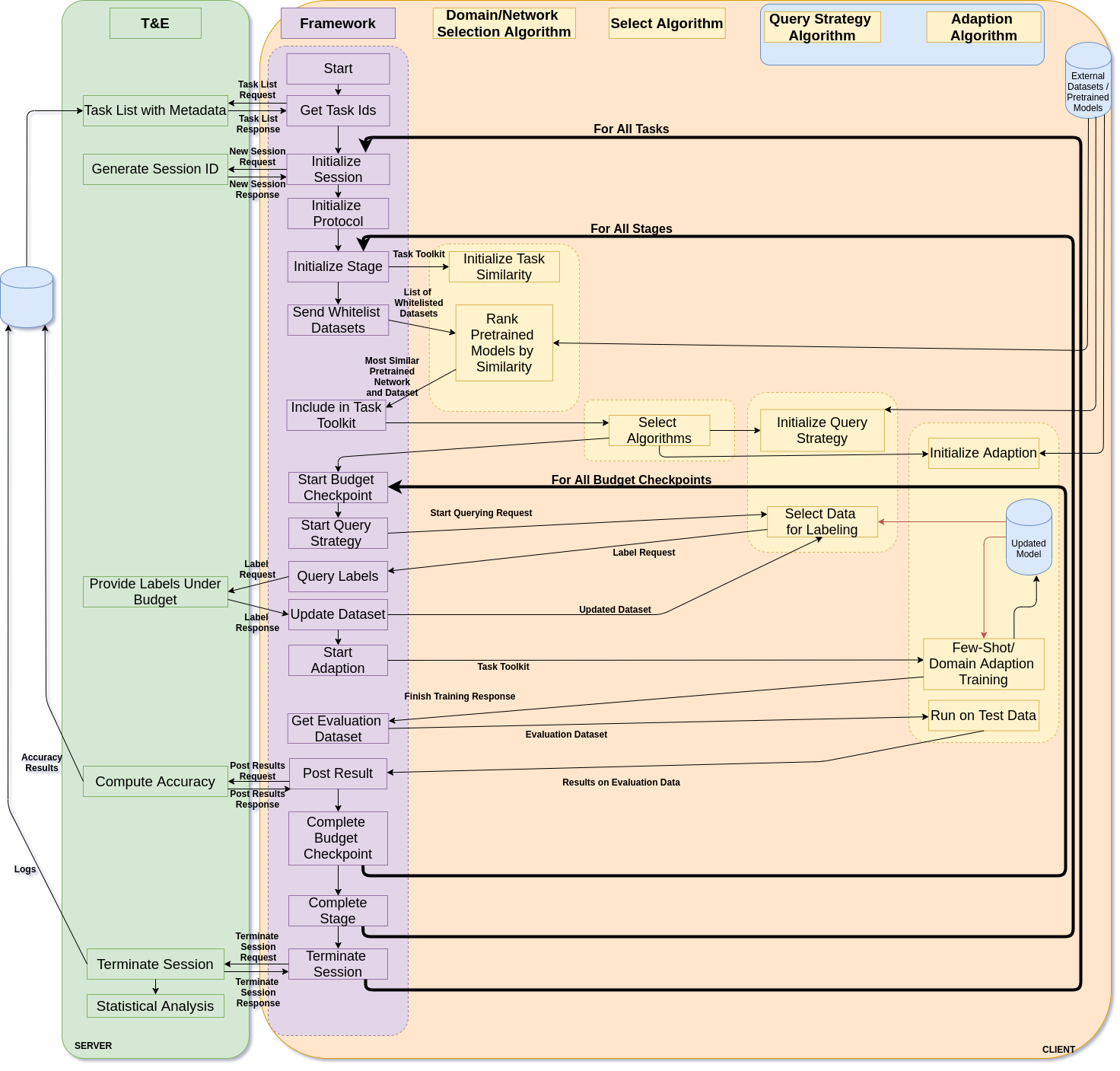
Learn tasks
The task consists for two datasets, one for each stage which we call the target dataset for the stage.
We are given a whitelist of external datasets (custom to this task) that we can use for this task and we load all
whitelisted datasets and pretrained models.
During each stage, we select which one is closest to the target dataset (the dataset at the
current stage) and call that the source dataset and source model. After than, we select the best algorithms
for query strategy and adaption based on the source dataset and the target dataset. You may override these and force
a specific algorithm in learn/protocol/learn_protocol.py. Note: this is very useful for testing specific algorithms.
Currently, template algorithms are used unless otherwise specified.
For the active learning, we are given seed labels on the target dataset (one per class). We are also given a set of budgets for the stage and these budgets are for the number of labels you may have and once you have reached the budget, you must do an evaluation. Within each budget, we run a a query strategy algorithm to select the data that we want labeled and then a classification algorithm (either few-shot or domain adaption).
Each stage is run in serial (so once all budgets for one stage are done, you move onto the next stage).
The datasets are broken down into external datasets, development datasets, and evaluation datasets. The
source datasets are either from a previous stage or from the whitelisted external datasets. External datasets
come with labels and, if on the whitelist, can be used during the task and pretrained models from
those datasets can also be used.
Protocol (framework)
The protocol runs the entire problem and the control is flow is defined in learn/protocol/learn_protocol.py.
The parameters for running the protocol are defined in learn/protocol/learn_config.py. You may edit these
parameter to get it working on your local machine. You will need to at least specify the directory of the data.
Contributing an algorithm
To contribute an algorithm, please make a copy of the folder for the template algorithm most appropriate for the
algorithm you want to add. For example, if you want to add a few-shot image classification algorithm,
templateImageClassification would be most appropriate.
The templates are random baselines for the algorithm and can show you what the input outputs are for the algorithms.
Image Classification
You must train your network in the SelectNetworkAndDataset step. You will be provides a semi-supervised to
use in pytorch dataset style. You can override the transformers to set the transform and prepare the data
for your networks. Please free all cuda memory you have taken up at the end of this function.
The second step is inference and you must infer labels on the evaluation dataset. The evaluation dataset
is provided and you may do transductive learning (you may also use the unlabeled test data during training).
The major constraint is that the output of this function needs to be in the format specified here.
Toolset
The toolset contains datasets, functions, and parameters useful to the protocol and algorithms. You will be adding your parameters as well. Check the template for the useful tools in the toolset for your algorithm.
Using Docker
Building Docker Image
Building development Branch
The docker image uses deploy tokens for building framework and learn repository. To learn more about the deploy tokens and their application refer to the following article. To build a docker image use
docker build -t learn_aug_eval:test --build-arg FRAMEWORK_TOKEN=<FRAMEWORK_TOKEN> --build-arg LEARN_TOKEN=<LEARN_TOKEN> --build-arg FRAMEWORK_SHA=<FRAMEWORK_SHA> --build-arg LEARN_SHA=<LEARN_SHA>.where <FRAMEWORK_SHA> and <LEARN_SHA> are git hashes used in the repo and <FRAMEWORK_TOKEN> and <LEARN_TOKEN> are available on request
Building Other Branch
The docker image uses deploy tokens for building framework and learn repository. To build a docker image use
docker build -t learn_aug_eval:test --build-arg FRAMEWORK_TOKEN=<FRAMEWORK_TOKEN> --build-arg LEARN_TOKEN=<LEARN_TOKEN> --build-arg LEARN_BRANCH=<BRANCH_NAME>.where <FRAMEWORK_TOKEN> and <LEARN_TOKEN> are available on request and <BRANCH_NAME> is the branch that you would like to dockerize.
Running The Agent
To run the container use
docker run -it --gpus=all --env-file env.list --shm-size 24g --mount type=bind,source="${HOME}"/lwll_datasets,target=/root/lwll_datasets --name=learn_aug_eval learn_aug_eval:testwhere ${HOME}/lwll_datasets contains the datasets used for evaluation
Adding you own datasets
TBD.
Copyright
This material is based on research sponsored by DARPA under agreement number FA8750-19-1-0504. The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright notation thereon.